
Memory Management
(Initial document by Mark Maunder, IATTC)
ADMB uses a number of temporary files if the memory is not large enough and these are found in the directory where your model is (cmpdiff.tmp, gradfil1.tmp, and gradfil2.tmp). In addition to writing to these files, the computer will also use the virtual memory that you have allocated on the hard disk.
The following command line options control the memory size for the given buffers. You can use the command line to change the size of the buffer (most recent version, otherwise you will have to change it in your code), if the buffer is bigger than the amount of memory used by ADMB then it won’t write to the temporary file. However, if you make the buffer too big then you computer won’t have enough memory and will write to the virtual memory on the hard disk.
| Buffer | command line
|
temp file |
| CMPDIF_BUFFER_SIZE | -cbs | cmpdiff.tmp |
| GRADSTACK_BUFFER_SIZE | -gbs | gradfil1.tm |
Gradfil2.tmp was intended to be a second file (presumably on a different partition) that gets written to when the first disk partition is full. It was pointed to by the environment string TMP1. This was back when 300MB was a large hard drive.
Method to investigate memory allocation:
1) Open windows explorer in the directory of the model, sort in descending order by file type so that the temporary files will appear at the top (note that they will only appear when the model is running).
2) Open the task manager and click the performance tab so you can see the memory being used. This is the total memory including virtual memory, so you will have to know how much real memory your computer has and compare the memory usage with this number. The CPU usage is also useful to watch, because if the computer is writing to disk, the CPU usage goes down to about 10% indicating that you model is not running optimally.
3) Run your model with guesses for –cbs and –gbs
4) While the model is running check to see if the files cmpdiff.tmp and gradfil1.tmp have a size greater than zero. If this is true, increase –cbs and –gbs, appropriately and try again. Note that these files may not get written to directly after the model is initiated so it is a good idea to keep watching for a while (at least until ADMB has written one set of output). You will also need to refresh the windows explorer display (from the view menu) each time you want to check the size of the files. Check the amount of memory in the task manager and if it is more than the memory on you computer then decrease either –cbs and –gbs and try again. Note that decreasing either –cbs and –gbs when its respective temporary file has a size greater than zero will not help.
5) If you find that your computer does not have enough memory you will have to make your code more efficient (see appendix I). In the case that you can not make the model more efficient, I don’tknow what is more efficient,writing to virtual memory or writing to the ADMB temporary files.
Another memory control you can set is the ARRAY_MEMBLOCK_SIZE using -ams. Fortunately, it is easy to determine the correct size for this. Start off with a low number and keep increasing it until you don’t get the error message “Memory allocation error in grad_stack constructor trying to allocate 3935228928 bytes” or something like that.
Here is an example of code changes for a likelihood and the analytical formula for the sd
Initial code
sigmaCatch = sqrt( elem_prod( log(catchobs+0.1)-log(catchest+0.1),log(catchobs+0.1)-log(catchest+0.1))/nobs));
catchlike = nobs*log(sigmaCatch) + sum(elem_prod(log(catchobs+0.1)-log(catchest+0.1),log(catchobs+0.1)-log(catchest+0.1)))/(2*sigmaCatch*sigmaCatch);
Modified code
catchlike_temp=log(catchobs+0.1)-log(catchest+0.1);
catchlike_temp=elem_prod(catchlike_temp,catchlike_temp);
sigmaCatch = sqrt(sum(catchlike_temp)/nobs);
catchlike = nobs*log(sigmaCatch) +sum(catchlike_temp)/(2*sigmaCatch*sigmaCatch) ;
The code was a little more complex than above (a few things were removed to make it clearer) and you could make a couple of more changes to make it even more efficient (i.e. the sum should be done once and could be accomplished by the matrix operation catchlike_temp* catchlike_temp and leaving out the catchlike_temp=elem_prod(catchlike_temp,catchlike_temp); step).
Appendix I: Coding efficiencies
When using AD Model Builder, for each computational operation a derivative is also calculated, therefore reducing the number of calculations often greatly reduce the computation time. Listed below are a number of simple ways to reduce the number of calculations.
1) If a value is going to be fixed throughout the estimation procedure, define it in the DATA_SECTION so derivatives are not calculated for this value and the calculations should be done in the PRELIMINARY_CALCS_SECTION so that the value is only calculated once.
2) Only evaluate likelihoods and priors when the relevant parameters are being estimated.
3) Only update derived values (e.g. mean length at age) when the relevant parameters are being estimated
4) Modify equations so that any operation that is common to more than a single calculation is only used once. e.g. 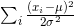 should be changed to
should be changed to 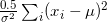 reducing the number of operations and derivative calculations from i*6-1 to i*3 +2.
reducing the number of operations and derivative calculations from i*6-1 to i*3 +2.
5) If a value is going to be used in more than one place, define a temporary parameter to hold the value so that it is only calculated once. If you have a large amount of memory this may be more efficient, but if the computer needs to use virtual memory this may be less efficient. Note that any time that virtual memory is used the time required for the estimation procedure will greatly increase.
6) AD Model Builder has precompiled adjoint code for the derivatives of commonly used array and matrix operations, therefore loops should be replaced with matrix algebra wherever possible. For example, 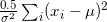 should be coded with ( (0.5)/(σ*σ) )*sum( elem_prod( (x-m) ) ). To be more efficient, the equation could be replaced with
should be coded with ( (0.5)/(σ*σ) )*sum( elem_prod( (x-m) ) ). To be more efficient, the equation could be replaced with 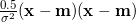 , where x and m are vectors of length i (one of the sets of brackets being transposed, which ADMB does automatically). Note that the ADMB function norm2 could be used for this calculation,
, where x and m are vectors of length i (one of the sets of brackets being transposed, which ADMB does automatically). Note that the ADMB function norm2 could be used for this calculation, 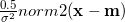 which would be written as ( (0.5)/(σ*σ))*norm2(x-m).
which would be written as ( (0.5)/(σ*σ))*norm2(x-m).
7) ADMB has a method for profiling the memory usage in the code. Essentially you set the memory very small (-gbs 1000) then see how much memory is written to disk in two parts of the code
use
cout<<temp<<endl;